The observe of counting traces within the record is normally followed by means of the builders to resolve the duration in their code or this system. They do in an effort to in finding out the potency of this system, this system having fewer traces acting the similar activity in comparison to this system of better traces is believed to be extra environment friendly.
In Linux, there are other the best way to depend the choice of traces within the recordsdata, all of those strategies are mentioned on this article intimately.
How to depend traces within the record in Linux
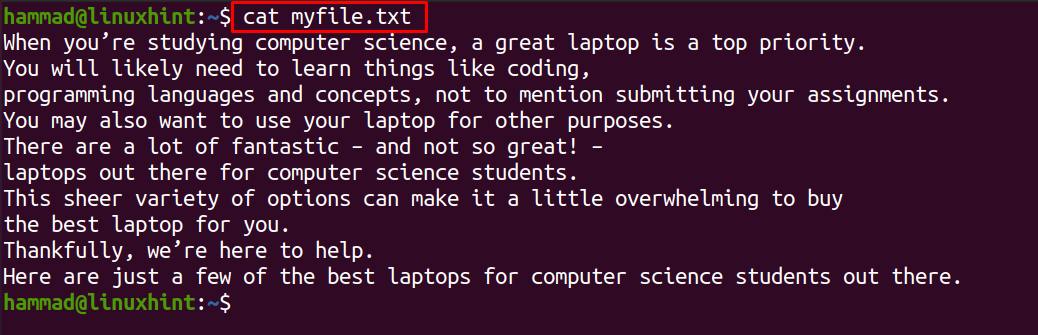
We have a textual content record in the house listing with the title “myfile.txt”, to show the contents of the textual content record, use the command:
Method 1: Using the wc command
The one way to depend the choice of traces is by means of the use of the “wc” command with the “-l” flag which is used to show the depend of traces:

You too can use the wc command with the cat command to show the depend of traces of a record:

Method 2: Using the awk command
Another way to depend the traces of the record in Linux is by means of the use of the command of awk:
$ awk ‘END{print NR}’ myfile.txt

Method 3: Using the sed command
The “sed” command will also be utilized in Linux to show the road depend of the record, using the sed command for the aim of showing various traces is discussed underneath:

Method 4: Using the Grep command
The “grep” command is used to look, however it may be used for counting the choice of traces in addition to to show them, for this goal, run the next command and substitute the “myfile.txt” along with your record title within the command:
$ grep -c “.*” myfile.txt

In the above command, we’ve got used the “-c” flag which counts the choice of traces and “.*” is used as an ordinary development or we will say to determine the strings within the record, in a different way to make use of the grep command such that it additionally presentations record title in output is using the “-H” flag:
$ grep -Hc “.*” myfile.txt

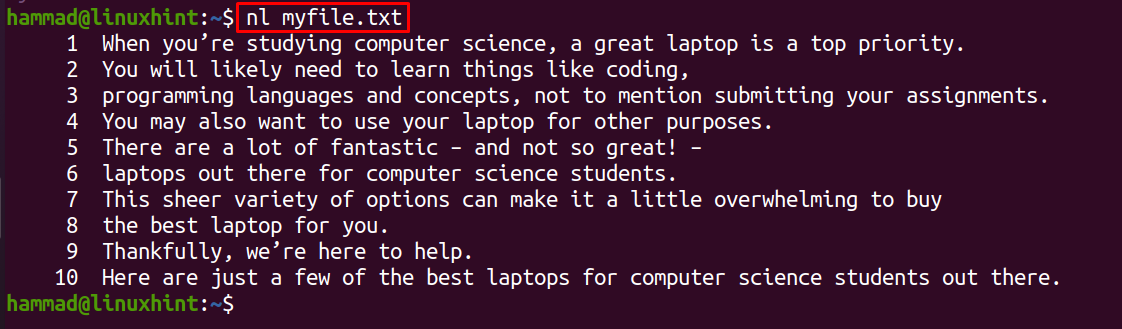
Method 5: Using the nl command
The quantity line command (nl) is used to show the numbered bullets with the traces of the record:
If you need to show simply the choice of traces, then use the awk command with the nl command:
$ nl myfile.txt | tail -1 | awk ‘{print $1}’

Method 6: Using the Perl language command:
Perl language command will also be used for the counting of the traces of the recordsdata in Linux, to make use of Perl command to depend the traces of the record “myfile.txt”, execute the command:
$ perl -lne ‘END { print $. }’ myfile.txt

Method 7: Using While loop
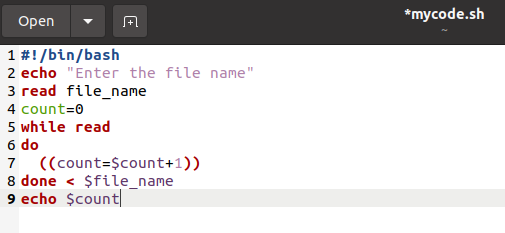
Another maximum often used way to depend the choice of traces of the massive recordsdata is the use of the whilst loop. Type the next bash script within the textual content record, and put it aside with .sh extension:
#!/bin/bash
echo “Enter the file name”
learn file_name
depend=0
whilst learn
do
((depend=$depend+1))
accomplished < $file_name
echo $depend
Execute the bash record the use of the bash command:
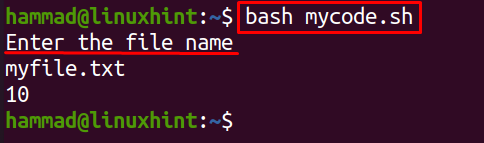
In the above output, at the execution of the command, it asks for the record title whose traces are to be counted, varieties the record title, in our case, it’s “myfile.txt”, so it presentations the consequences.
Conclusion
To calculate the productiveness of the programmers, the principle parameter is the duration in their code, which can also be measured by means of counting the traces of the code record. In Linux, we will depend traces in numerous tactics which might be mentioned on this article, essentially the most often used means is the wc command means.