High Availability cluster, also known as failover cluster or active-passive cluster, is one of the most widely used cluster types in a production environment to have continuous availability of services even one of the cluster nodes fails.
In technical, if the server running application has failed for some reason (ex: hardware failure), cluster software (pacemaker) will restart the application on the working node.
Failover is not just restarting an application; it is a series of operations associated with it, like mounting filesystems, configuring networks, and starting dependent applications.
Environment
Here, we will configure a failover cluster with Pacemaker to make the
Apache (web) server as a highly available application.
Here, we will configure the Apache web server, filesystem, and networks as resources for our cluster.
For a filesystem resource, we would be using shared storage coming from iSCSI storage.
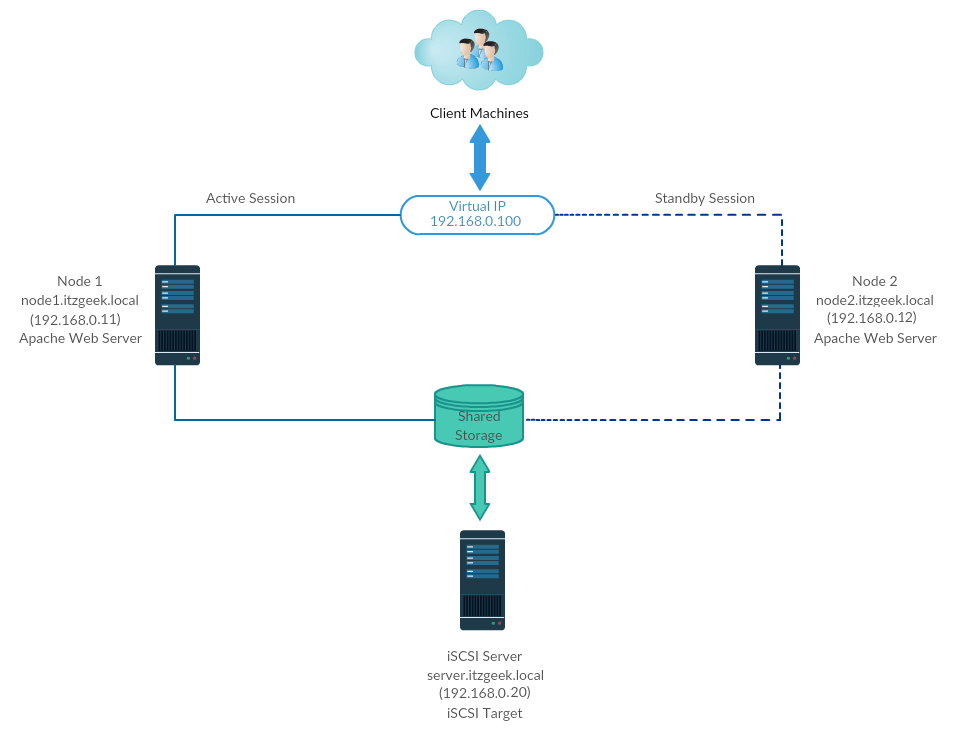
All are running on VMware Workstation.
Shared Storage
Shared storage is one of the critical resources in the high availability cluster as it stores the data of a running application. All the nodes in a cluster will have access to the shared storage for the latest data.
SAN storage is the widely used shared storage in a production environment. Due to resource constraints, for this demo, we will configure a cluster with iSCSI storage for a demonstration purpose.
Install Packages
iSCSI Server
[root@storage ~]# dnf install -y targetcli lvm2
Cluster Nodes
dnf install -y iscsi-initiator-utils lvm2
Setup Shared Disk
Let’s list the available disks in the iSCSI server using the below command.
[root@storage ~]# fdisk -l | grep -i sd
Output:
Disk /dev/sda: 100 GiB, 107374182400 bytes, 209715200 sectors
/dev/sda1 * 2048 2099199 2097152 1G 83 Linux
/dev/sda2 2099200 209715199 207616000 99G 8e Linux LVM
Disk /dev/sdb: 10 GiB, 10737418240 bytes, 20971520 sectors
From the above output, you can see that my system has a 10GB hard disk (/dev/sdb).
Here, we will create an LVM on the iSCSI server to use as shared storage for our cluster nodes.
[root@storage ~]# pvcreate /dev/sdb
[root@storage ~]# vgcreate vg_iscsi /dev/sdb
[root@storage ~]# lvcreate -l 100%FREE -n lv_iscsi vg_iscsi
Create Shared Storage
Get the nodes initiator’s details.
cat /etc/iscsi/initiatorname.iscsi
Node 1:
InitiatorName=iqn.1994-05.com.redhat:121c93cbad3a
Node 2:
InitiatorName=iqn.1994-05.com.redhat:827e5e8fecb
Enter the below command to get an iSCSI CLI for an interactive prompt.
[root@storage ~]# targetcli
Output: Warning: Could not load preferences file /root/.targetcli/prefs.bin. targetcli shell version 2.1.fb49 Copyright 2011-2013 by Datera, Inc and others. For help on commands, type 'help'. /> cd /backstores/block /backstores/block> create iscsi_shared_storage /dev/vg_iscsi/lv_iscsi Created block storage object iscsi_shared_storage using /dev/vg_iscsi/lv_iscsi. /backstores/block> cd /iscsi /iscsi> create Created target iqn.2003-01.org.linux-iscsi.storage.x8664:sn.eac9425e5e18. Created TPG 1. Global pref auto_add_default_portal=true Created default portal listening on all IPs (0.0.0.0), port 3260. /iscsi> cd iqn.2003-01.org.linux-iscsi.storage.x8664:sn.eac9425e5e18/tpg1/acls /iscsi/iqn.20...e18/tpg1/acls> create iqn.1994-05.com.redhat:121c93cbad3a Created Node ACL for iqn.1994-05.com.redhat:121c93cbad3a /iscsi/iqn.20...e18/tpg1/acls> create iqn.1994-05.com.redhat:827e5e8fecb Created Node ACL for iqn.1994-05.com.redhat:827e5e8fecb /iscsi/iqn.20...e18/tpg1/acls> cd /iscsi/iqn.2003-01.org.linux-iscsi.storage.x8664:sn.eac9425e5e18/tpg1/luns /iscsi/iqn.20...e18/tpg1/luns> create /backstores/block/iscsi_shared_storage Created LUN 0. Created LUN 0->0 mapping in node ACL iqn.1994-05.com.redhat:827e5e8fecb Created LUN 0->0 mapping in node ACL iqn.1994-05.com.redhat:121c93cbad3a /iscsi/iqn.20...e18/tpg1/luns> cd / /> ls o- / ......................................................................................................................... [...] o- backstores .............................................................................................................. [...] | o- block .................................................................................................. [Storage Objects: 1] | | o- iscsi_shared_storage .............................................. [/dev/vg_iscsi/lv_iscsi (10.0GiB) write-thru activated] | | o- alua ................................................................................................... [ALUA Groups: 1] | | o- default_tg_pt_gp ....................................................................... [ALUA state: Active/optimized] | o- fileio ................................................................................................. [Storage Objects: 0] | o- pscsi .................................................................................................. [Storage Objects: 0] | o- ramdisk ................................................................................................ [Storage Objects: 0] o- iscsi ............................................................................................................ [Targets: 1] | o- iqn.2003-01.org.linux-iscsi.storage.x8664:sn.eac9425e5e18 ......................................................... [TPGs: 1] | o- tpg1 ............................................................................................... [no-gen-acls, no-auth] | o- acls .......................................................................................................... [ACLs: 2] | | o- iqn.1994-05.com.redhat:121c93cbad3a .................................................................. [Mapped LUNs: 1] | | | o- mapped_lun0 .................................................................. [lun0 block/iscsi_shared_storage (rw)] | | o- iqn.1994-05.com.redhat:827e5e8fecb ................................................................... [Mapped LUNs: 1] | | o- mapped_lun0 .................................................................. [lun0 block/iscsi_shared_storage (rw)] | o- luns .......................................................................................................... [LUNs: 1] | | o- lun0 ......................................... [block/iscsi_shared_storage (/dev/vg_iscsi/lv_iscsi) (default_tg_pt_gp)] | o- portals .................................................................................................... [Portals: 1] | o- 0.0.0.0:3260 ..................................................................................................... [OK] o- loopback ......................................................................................................... [Targets: 0] /> saveconfig Configuration saved to /etc/target/saveconfig.json /> exit Global pref auto_save_on_exit=true Last 10 configs saved in /etc/target/backup/. Configuration saved to /etc/target/saveconfig.json
Enable and restart the Target service.
[root@storage ~]# systemctl enable target
[root@storage ~]# systemctl restart target
Configure the firewall to allow iSCSI traffic.
[root@storage ~]# firewall-cmd --permanent --add-port=3260/tcp
[root@storage ~]# firewall-cmd --reload
Discover Shared Storage
On both cluster nodes, discover the target using the below command.
iscsiadm -m discovery -t st -p 192.168.0.20
Output:
192.168.0.20:3260,1 qn.2003-01.org.linux-iscsi.storage.x8664:sn.eac9425e5e18
Now, login to the target storage with the below command.
iscsiadm -m node -T iqn.2003-01.org.linux-iscsi.storage.x8664:sn.eac9425e5e18 -p 192.168.0.20 -l
Output: Logging in to [iface: default, target: iqn.2003-01.org.linux-iscsi.storage.x8664:sn.eac9425e5e18, portal: 192.168.0.20,3260] Login to [iface: default, target: iqn.2003-01.org.linux-iscsi.storage.x8664:sn.eac9425e5e18, portal: 192.168.0.20,3260] successful.
Restart and enable the initiator service.
systemctl restart iscsid
systemctl enable iscsid
Setup Cluster Nodes
Shared Storage
Go to all of your cluster nodes and check whether the new disk from the iSCSI server is visible or not.
In my nodes, /dev/sdb is the shared disk from iSCSI storage.
fdisk -l | grep -i sd
Output:
Disk /dev/sda: 100 GiB, 107374182400 bytes, 209715200 sectors
/dev/sda1 * 2048 2099199 2097152 1G 83 Linux
/dev/sda2 2099200 209715199 207616000 99G 8e Linux LVM
Disk /dev/sdb: 10 GiB, 10733223936 bytes, 20963328 sectors
On any one of your nodes (Ex, node1), create a filesystem for the Apache webserver to hold the website files. We will create a filesystem with LVM.
[root@node1 ~]# pvcreate /dev/sdb
[root@node1 ~]# vgcreate vg_apache /dev/sdb
[root@node1 ~]# lvcreate -n lv_apache -l 100%FREE vg_apache
[root@node1 ~]# mkfs.ext4 /dev/vg_apache/lv_apache
Now, go to another node and run below commands to detect the newly filesystem.
[root@node2 ~]# pvscan
[root@node2 ~]# vgscan
[root@node2 ~]# lvscan
Finally, verify the LVM we created on node1 is available to you on another node (Ex. node2) using the below commands.
ls -al /dev/vg_apache/lv_apache
and
[root@node2 ~]# lvdisplay /dev/vg_apache/lv_apache
Output: _You should see /dev/vg_apache/lv_apache on node2.holhol24.local_ --- Logical volume --- LV Path /dev/vg_apache/lv_apache LV Name lv_apache VG Name vg_apache LV UUID gXeaoB-VlN1-zWSW-2VnZ-RpmW-iDeC-kQOxZE LV Write Access read/write LV Creation host, time node1.holhol24.local, 2020-03-30 08:08:17 -0400 LV Status NOT available LV Size 9.96 GiB Current LE 2551 Segments 1 Allocation inherit Read ahead sectors auto
If the system doesn’t display the logical volume or the device file not found, then consider rebooting the second node.
Host Entry
Make a host entry about each node on all nodes. The cluster will be using the hostname to communicate with each other.
vi /etc/hosts
Host entries will be something like below.
192.168.0.11 node1.holhol24.local node1
192.168.0.12 node2.holhol24.local node2
Install Packages
Cluster packages are available in the High Availability repository. So, configure the High Availability repository on your system.
CentOS 8
dnf config-manager --set-enabled HighAvailability
RHEL 8
Enable Red Hat subscription on RHEL 8 and then enable a High Availability repository to download cluster packages form Red Hat.
subscription-manager repos --enable=rhel-8-for-x86_64-highavailability-rpms
Install cluster packages (pacemaker) with all available fence agents on all nodes using the below command.
dnf install -y pcs fence-agents-all pcp-zeroconf
Add a firewall rule to allow all high availability application to have proper communication between nodes. You can skip this step if the system doesn’t have firewalld enabled.
firewall-cmd --permanent --add-service=high-availability
firewall-cmd --add-service=high-availability
firewall-cmd --reload
Set a password for the hacluster user.
This user account is a cluster administration account. We suggest you set the same password for all nodes.
passwd hacluster
Start the cluster service and enable it to start automatically on system startup.
systemctl start pcsd
systemctl enable pcsd
Remember: You need to run the above commands on all of your cluster nodes.
Create a High Availability Cluster
Authorize the nodes using the below command. Run the below command in any one of the nodes to authorize the nodes.
[root@node1 ~]# pcs host auth node1.holhol24.local node2.holhol24.local
Output: Username: hacluster Password: node1.holhol24.local: Authorized node2.holhol24.local: Authorized
Create a cluster. Change the name of the cluster itzgeek_cluster as per your requirement.
[root@node1 ~]# pcs cluster setup itzgeek_cluster --start node1.holhol24.local node2.holhol24.local
Output:
No addresses specified for host 'node1.holhol24.local', using 'node1.holhol24.local'
No addresses specified for host 'node2.holhol24.local', using 'node2.holhol24.local'
Destroying cluster on hosts: 'node1.holhol24.local', 'node2.holhol24.local'...
node1.holhol24.local: Successfully destroyed cluster
node2.holhol24.local: Successfully destroyed cluster
Requesting remove 'pcsd settings' from 'node1.holhol24.local', 'node2.holhol24.local'
node1.holhol24.local: successful removal of the file 'pcsd settings'
node2.holhol24.local: successful removal of the file 'pcsd settings'
Sending 'corosync authkey', 'pacemaker authkey' to 'node1.holhol24.local', 'node2.holhol24.local'
node1.holhol24.local: successful distribution of the file 'corosync authkey'
node1.holhol24.local: successful distribution of the file 'pacemaker authkey'
node2.holhol24.local: successful distribution of the file 'corosync authkey'
node2.holhol24.local: successful distribution of the file 'pacemaker authkey'
Sending 'corosync.conf' to 'node1.holhol24.local', 'node2.holhol24.local'
node1.holhol24.local: successful distribution of the file 'corosync.conf'
node2.holhol24.local: successful distribution of the file 'corosync.conf'
Cluster has been successfully set up.
Starting cluster on hosts: 'node1.holhol24.local', 'node2.holhol24.local'...
Enable the cluster to start at the system startup.
[root@node1 ~]# pcs cluster enable --all
Output: node1.holhol24.local: Cluster Enabled node2.holhol24.local: Cluster Enabled
Use the below command to get the status of the cluster.
[root@node1 ~]# pcs cluster status
Output: Cluster Status: Stack: corosync Current DC: node1.holhol24.local (version 2.0.2-3.el8_1.2-744a30d655) - partition with quorum Last updated: Mon Mar 30 08:28:08 2020 Last change: Mon Mar 30 08:27:25 2020 by hacluster via crmd on node1.holhol24.local 2 nodes configured 0 resources configured PCSD Status: node1.holhol24.local: Online node2.holhol24.local: Online
Run the below command to get detailed information about the cluster which includes its resources, pacemaker status, and nodes details.
[root@node1 ~]# pcs status
Output: Cluster name: itzgeek_cluster WARNINGS: No stonith devices and stonith-enabled is not false Stack: corosync Current DC: node1.holhol24.local (version 2.0.2-3.el8_1.2-744a30d655) - partition with quorum Last updated: Mon Mar 30 08:33:37 2020 Last change: Mon Mar 30 08:27:25 2020 by hacluster via crmd on node1.holhol24.local 2 nodes configured 0 resources configured Online: [ node1.itzgeek.local node2.itzgeek.local ] No resources Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled
Fencing Devices
The fencing device is a hardware device that helps to disconnect the problematic node by resetting node / disconnecting shared storage from accessing it. This demo cluster is running on top of the VMware and doesn’t have any external fence device to set up. However, you can follow
this guide to set up a fencing device.
Since we are not using fencing, disable it (STONITH). You must disable fencing to start the cluster resources, but disabling STONITH in the production environment is not recommended.
[root@node1 ~]# pcs property set stonith-enabled=false
Cluster Resources
Prepare resources
Apache Web Server
Install Apache web server on both nodes.
dnf install -y httpd
Edit the configuration file.
vi /etc/httpd/conf/httpd.conf
Add below content at the end of the file on both cluster nodes.
SetHandler server-status
Require local
Edit the Apache web server’s logrotate configuration to tell not to use systemd as cluster resource doesn’t use systemd to reload the service.
Change the below line.
FROM:
/bin/systemctl reload httpd.service > /dev/null 2>/dev/null || true
TO:
/usr/sbin/httpd -f /etc/httpd/conf/httpd.conf -c "PidFile /var/run/httpd.pid" -k graceful > /dev/null 2>/dev/null || true
Now, we will use the shared storage for storing the web content (HTML) file. Perform below operation in any one of the nodes.
[root@node1 ~]# mount /dev/vg_apache/lv_apache /var/www/
[root@node1 ~]# mkdir /var/www/html
[root@node1 ~]# mkdir /var/www/cgi-bin
[root@node1 ~]# mkdir /var/www/error
[root@node1 ~]# restorecon -R /var/www
[root@node1 ~]# cat <<-END >/var/www/html/index.html
Hello, Welcome!. This Page Is Served By Red Hat Hight Availability Cluster
END
[root@node1 ~]# umount /var/www
Allow Apache service in the firewall on both nodes.
firewall-cmd --permanent --add-service=http
firewall-cmd --reload
Create Resources
Create a filesystem resource for the Apache server. Use the storage coming from the iSCSI server.
[root@node1 ~]# pcs resource create httpd_fs Filesystem device="/dev/mapper/vg_apache-lv_apache" directory="/var/www" fstype="ext4" --group apache
Output: Assumed agent name 'ocf:`heartbeat`:Filesystem' (deduced from 'Filesystem')
Create an IP address resource. This IP address will act as a virtual IP address for the Apache, and clients will use this ip address for accessing the web content instead of an individual node’s ip.
[root@node1 ~]# pcs resource create httpd_vip IPaddr2 ip=192.168.0.100 cidr_netmask=24 --group apache
Output: Assumed agent name 'ocf:`heartbeat`:IPaddr2' (deduced from 'IPaddr2')
Create an Apache resource to monitor the status of the Apache server that will move the resource to another node in case of any failure.
[root@node1 ~]# pcs resource create httpd_ser apache configfile="/etc/httpd/conf/httpd.conf" statusurl="http://127.0.0.1/server-status" --group apache
Output: Assumed agent name 'ocf:`heartbeat`:apache' (deduced from 'apache')
Check the status of the cluster.
[root@node1 ~]# pcs status
Output:
Cluster name: itzgeek_cluster
Stack: corosync
Current DC: node1.holhol24.local (version 2.0.2-3.el8_1.2-744a30d655) - partition with quorum
Last updated: Mon Mar 30 09:02:07 2020
Last change: Mon Mar 30 09:01:46 2020 by root via cibadmin on node1.holhol24.local
2 nodes configured
3 resources configured
Online: [ node1.itzgeek.local node2.itzgeek.local ]
Full list of resources:
Resource Group: apache
httpd_fs (ocf:?Filesystem): Started node1.holhol24.local
httpd_vip (ocf:?IPaddr2): Started node1.holhol24.local
httpd_ser (ocf:?apache): Started node1.holhol24.local
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
Verify High Availability Cluster
Once the cluster is up and running, point a web browser to the Apache virtual IP address. You should get a web page like below.
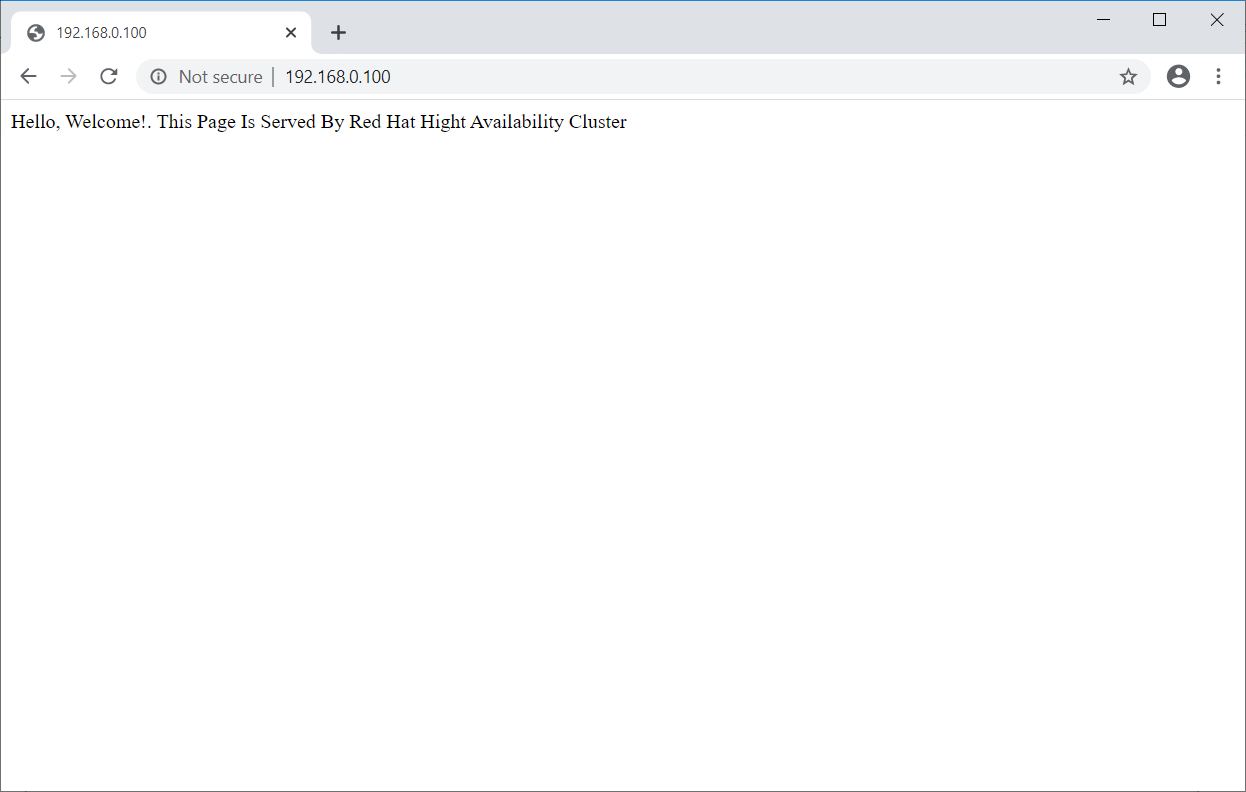
Test High Availability Cluster
Let’s check the failover of the resources by putting the active node (where all resources are running) in standby mode.
[root@node1 ~]# pcs node standby node1.holhol24.local
Important Cluster Commands
List cluster resources:
pcs resource status
Restart cluster resource:
pcs resource restart
Move the resource off a node:
pcs resource move
Put cluster in maintenance:
pcs property set maintenance-mode=true
Remove cluster from maintenance:
pcs property set maintenance-mode=false
Start the cluster node:
pcs cluster start
Stop cluster node:
pcs cluster stop
Start cluster:
pcs cluster start --all
Stop cluster:
pcs cluster stop --all
Destroy cluster:
pcs cluster destroy
Cluster Web User Interface
The pcsd web user interface helps you create, configure, and manage Pacemaker clusters.
The web interface will be accessible once you start pcsd service on the node and it is available on port number 2224.
https://node_name:2224
Login with cluster administrative user hacluster and its password.
Since we already have a cluster, click on Add Existing to add the existing Pacemaker cluster. In case you want to set up a new cluster, you can read the
official documentation.
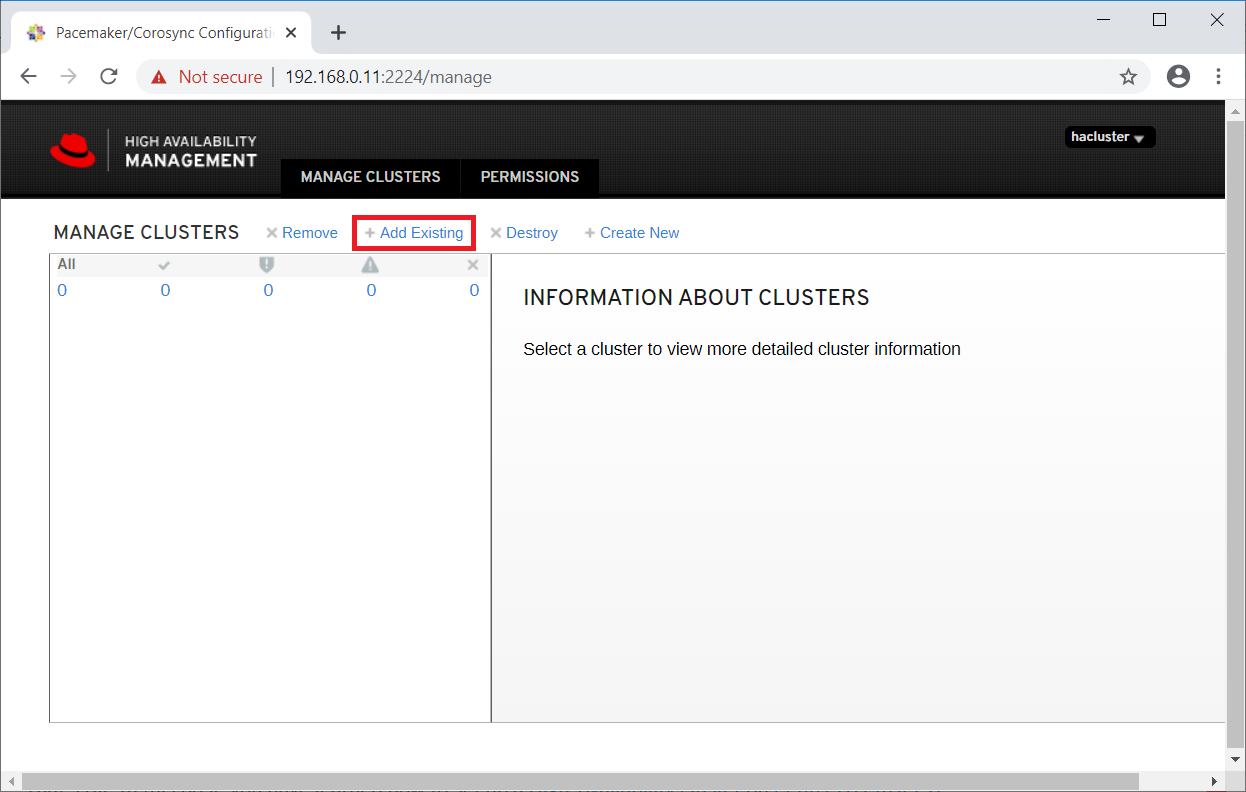
Enter any one of a cluster node to detect an existing cluster.
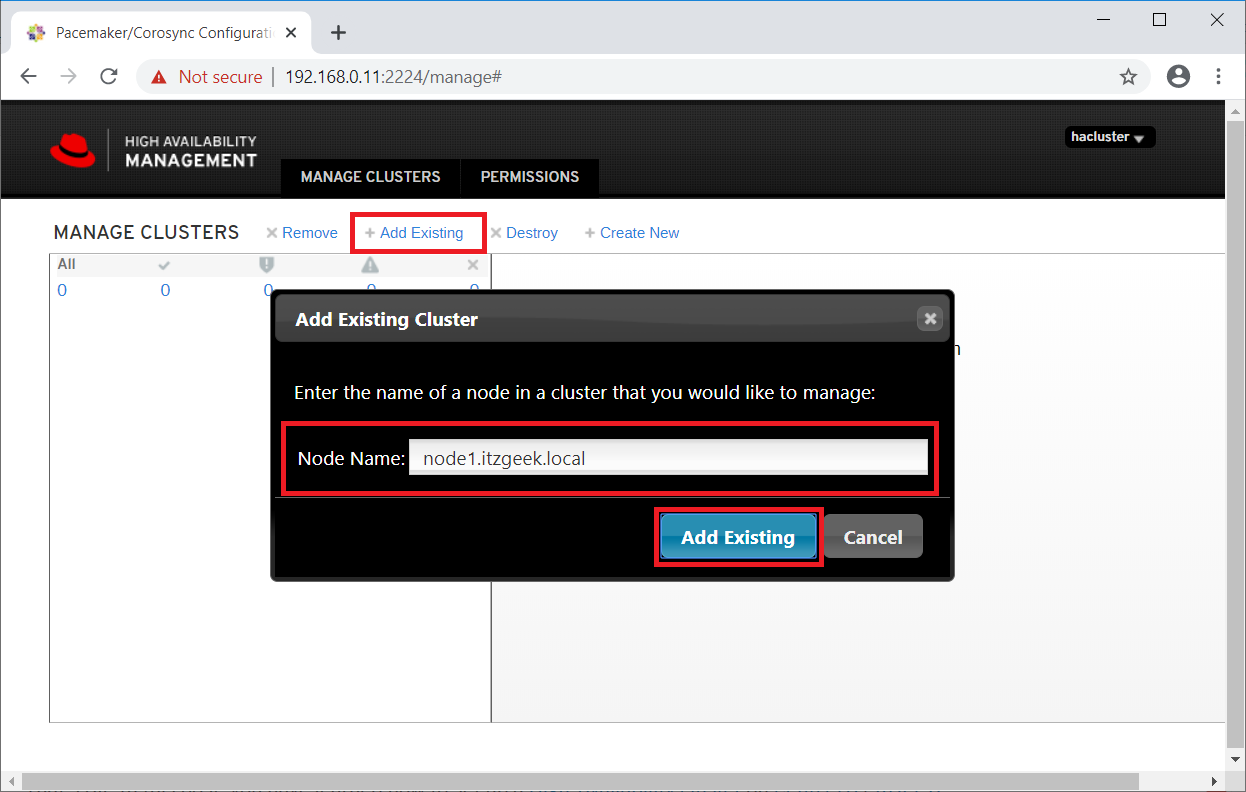
In a minute or two, you would see your existing cluster in the web UI.
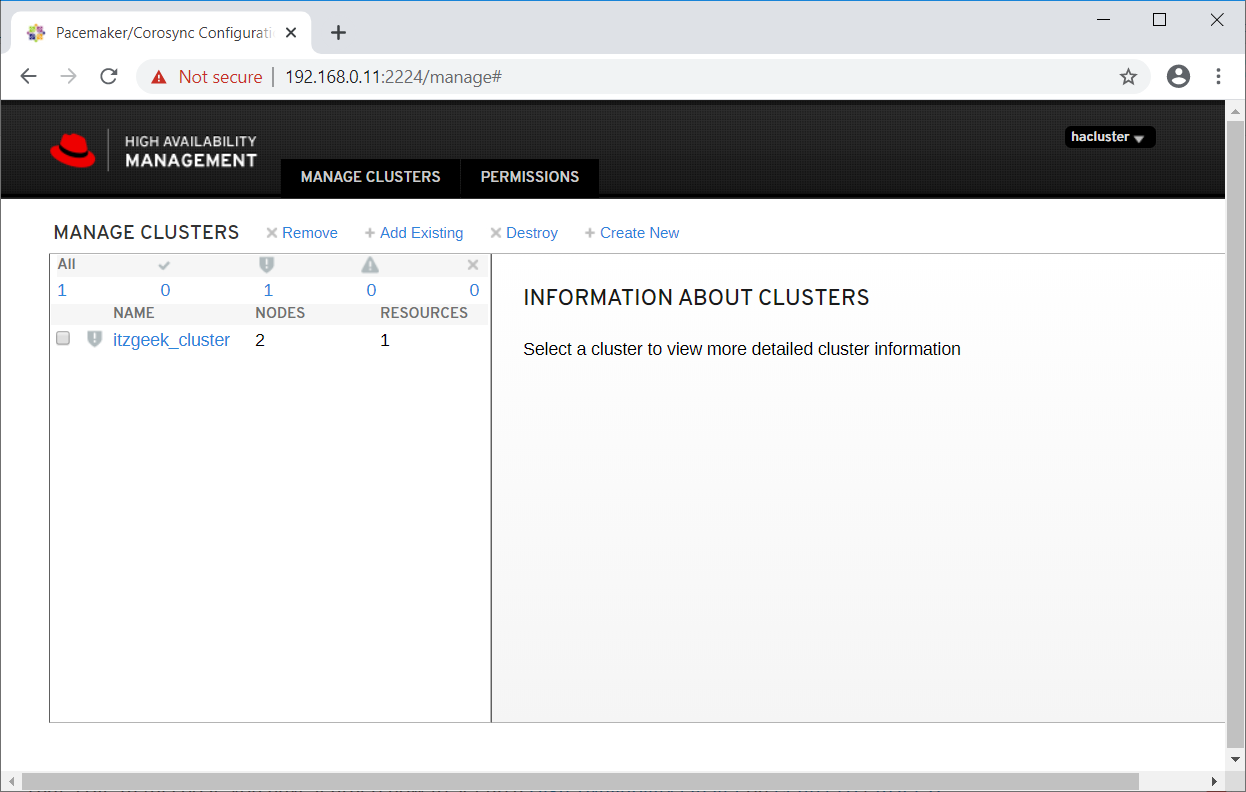
Select the cluster to know more about the cluster information.
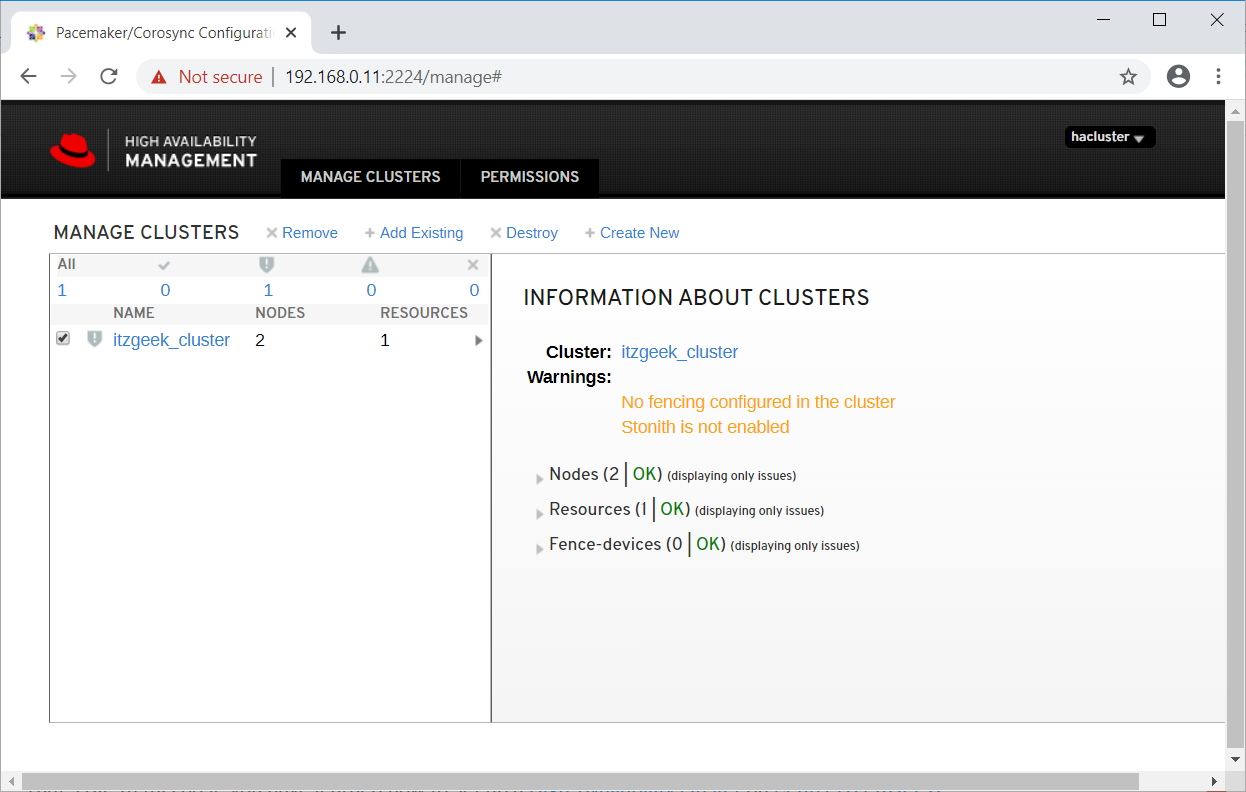
Click on the cluster name to see the details of the node.
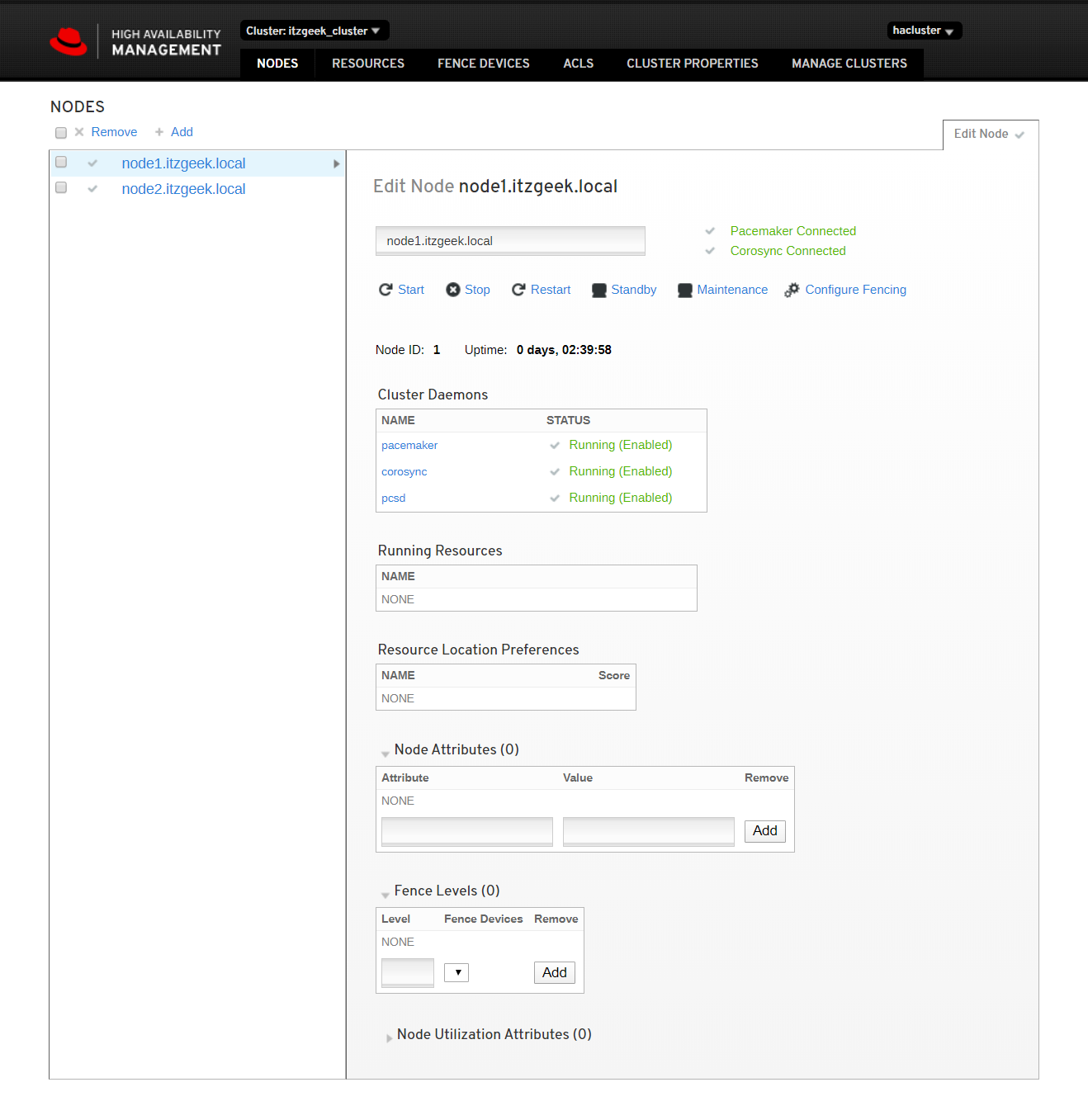
Click cluster resources to see the list of resources and their details.
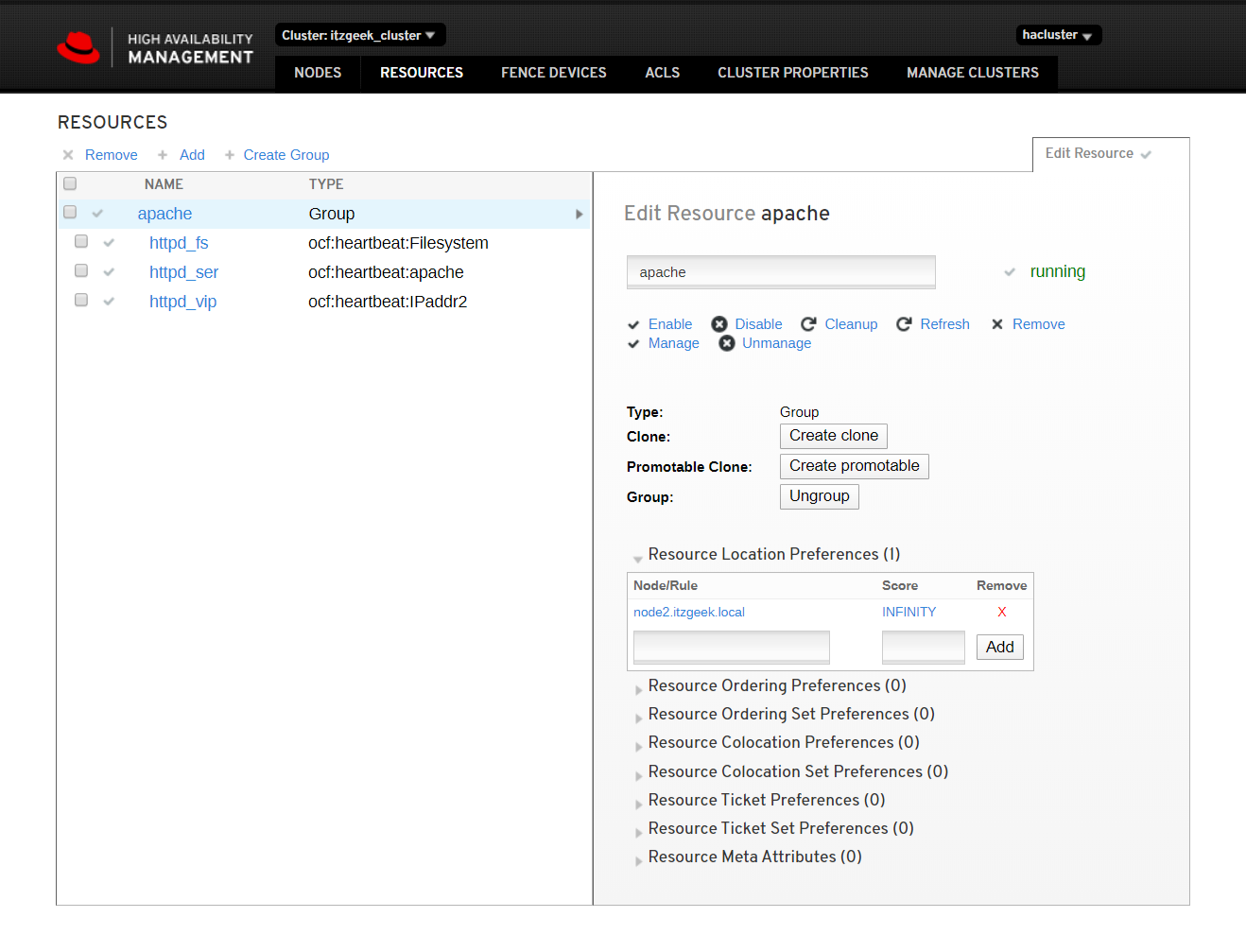
Reference:
Red Hat Documentation.
Conclusion
That’s All. In this post, you have learned how to set up a
High-Availability cluster on
CentOS 8 /
RHEL 8.