Dealing with PDF files can be quite a hassle at times since they are not very modifiable. Often one needs to extract a handful of specific pages from a huge document, and the whole errand can feel very laborious. This is exactly why we will be devoting this tutorial to show you the best methods and the finest tools you need to extract pages from PDF files in Linux.
Using an online tool
PDF files have become one of the most common means of documenting and distributing data. Owing to their popularity, many websites and programs are designed particularly to manipulate these files. Speaking of which, ILovePDF is a website devoted entirely to this purpose. It has many tools that you can use for free to split, merge, convert, organize, protect, and compress PDF files.
Since we want to extract pages from PDF files, we will use the PDF Splitter tool offered by the website as mentioned above. Once you have the PDF document you want to extract pages from, click here to visit the online PDF Splitter tool.
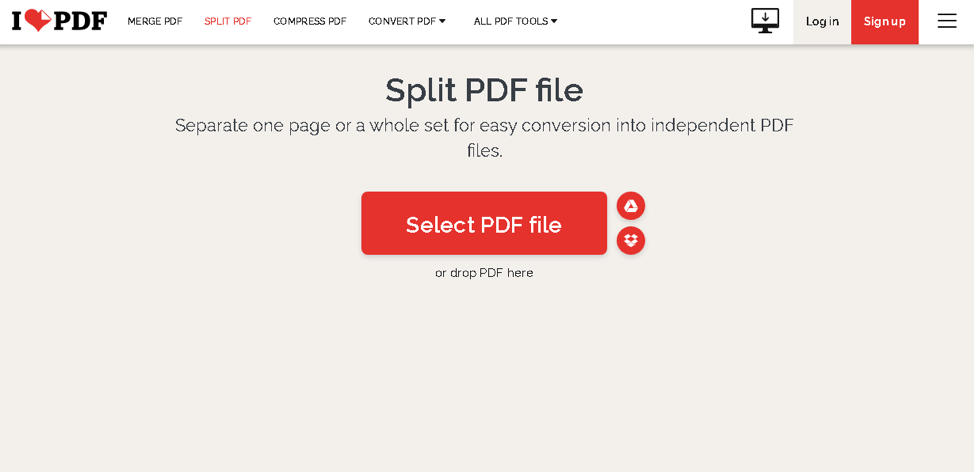
Click the Select PDF file button and navigate to your document. Once you have uploaded it, you can select whether you want to extract pages or split the file by range.
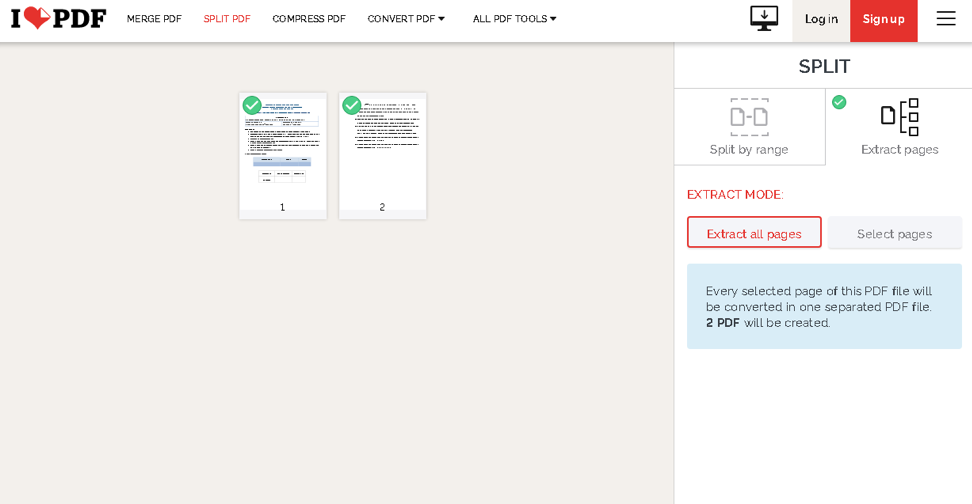
Go ahead and select the options you need from the buttons on the right side. Once you are done, click the Split PDF, and that should be it. It will initialize downloading a .zip file that contains your extracted pages.
ILovePDF also has a free downloadable app, but unfortunately, it is only available for Windows and macOS. However, that does not take away from its ability to help you extract pages from PDFs on Linux since you can use it online too. With that being said, you can now use a completely free online PDF splitting tool to select specific pages from PDF files and extract them without any trouble!
Using PDFShuffler
If for whatever reason – may it be due to privacy concerns or lack of functionality – the previous method did not convince you, fret not, as we have more favorable recommendations for you to try out.
One of which is PDFShuffler, a handy python-gtk app that lets its users manipulate PDF files easily. Its features include merging, splitting, cropping, rotating, and rearranging PDF files. The tool adds to its extensive functionality through its easy-to-grasp and intuitive graphical interface.
You can click here to download PDFShuffler from Source Forge, or you can do it the old-fashioned way through the command line. Navigate to the Activities menu or press Ctrl + Alt + T on your keyboard to open a new Terminal window.
Having done that, run the commands below to the first check for updates and then install PDFShuffler on your Linux system. (These commands are for Ubuntu 20.04, but other versions should not be too different from these).
$ sudo apt update
$ sudo apt install pdfshuffler
Once the installation is complete, find the newly installed software in the Activities menu and run it. The default screen should look something like the image below.
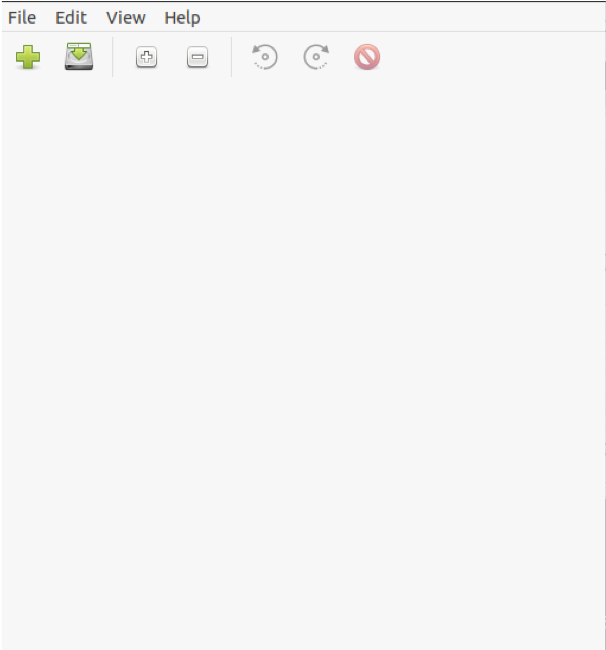
The next step is to input your PDF file into the program by clicking the File button and selecting the Add option from the drop-down menu.
Once done, configure your extraction settings and split the file. The output should give you the desired extracted pages from the input document.
Using PDFtk
If you have a special appreciation for command-line programs rather than ones with graphical interfaces, then PDFtk is the way to go. It is an efficient CLI solution for users that need to extract specific pages from PDF files. Let us look at how you can install it on various Linux distributions and how to use it.
Go back to your Terminal window or open a new one and run the following commands if you use Ubuntu or Debian.
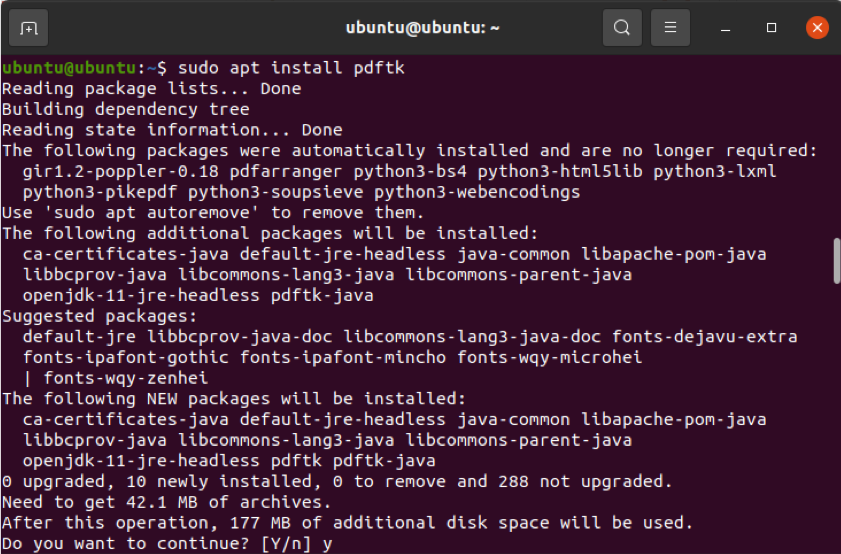
However, if you do not have the universe repository enabled, the command mentioned above will not work. You can enable this repository by running the command below.
$ sudo add-apt-repository universe
Having done that, go back to the first command to install PDFtk.
If you are using Arch Linux or one of its variants, run the command below. (PDFtk is easily accessible through the community repository).
Similarly, if you are on openSUSE, run the command below to install PDFtk.
$ sudo zypper install pdftk
Lastly, if you have snap enabled, you can get this tool through a snap command as well.
$ sudo snap install pdftk
Next, let us take a look at the usage of PDFtk. As we mentioned earlier, this is a CLI tool, so all you need to do is run a small command to get what you need.
$ pdftk input.pdf cat 3-4 output output_p3-4.pdf
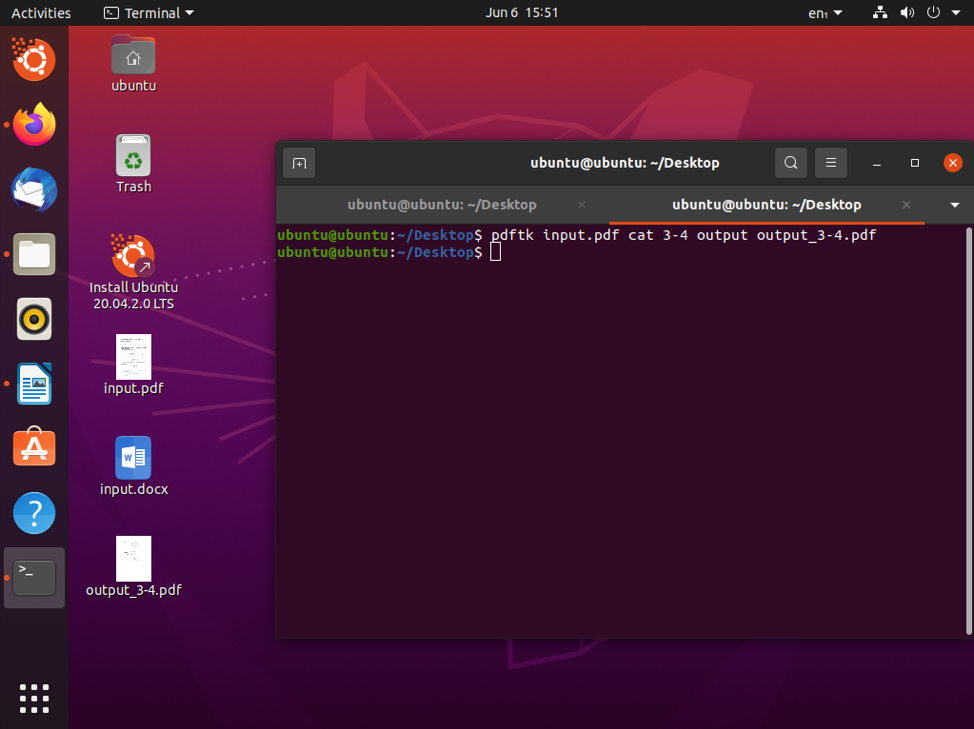
Now, what is going on in this command? First, input.pdf is the document that needs to be split. The 3-4 parameter specifies page number range, 3 to 4. Next, we have the output filename, which is output_p3-4.pdf. Simple enough, and you should get the hang of it in no time.
However, you may not be looking to split a PDF file by a page number range; rather, extracting a bunch of particular pages into separate PDF files. Worry not, as you can do that through this tool as well. All you need to do is make a slight change in the command we mentioned earlier. This change is shown below.
$ pdftk input.pdf cat 3 4 output output.pdf
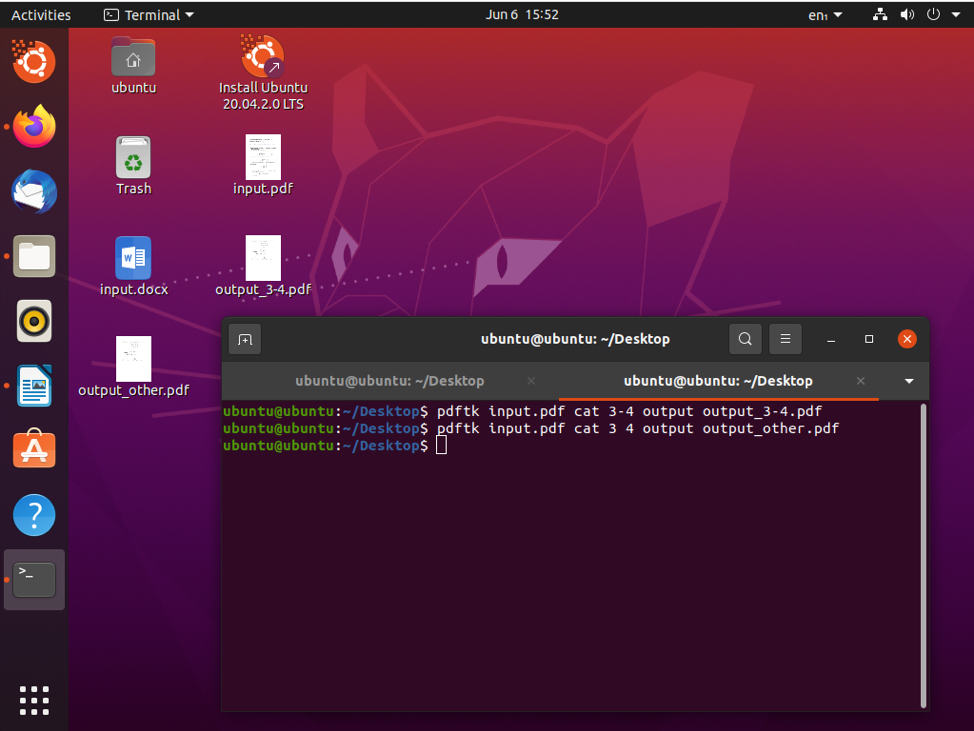
With that done, you can split pages 3 and 4 and save them as output.pdf.
Conclusion
In this guide, we went into great depth about how you can extract pages from PDF files. We looked at a handy online tool, then a downloadable GUI-based program, and lastly, a command-line solution. The tools mentioned above are rich in terms of features and ought to get the job done easily.